

ShuyaVision
[논문 리뷰] MobileNet V1, V2 본문
Mobile 및 Embedded System에서 사용할 수 있도록 개발된 MobileNet의 V1, V2에 대해 간단하게 알아본다.

MobileNet V1
Depthwise Separable Convolution
MobileNet model은 depthwise separable convolutions에 기반한다. 이는 depthwise convolusion과 pointwise convolution을 합친 것이다.
- depthwise convolution
Standard convolution을 factorize 해서 사용하는 방법이다. MobileNet에서는 각 input channnel에 대해 하나의 filter를 사용한다. 이 때 채널간의 정보 공유는 일어나지 않는다.
- pointwise convolution
depthwise convolution을 combine하기 위해 1x1 convolution을 수행하는 단계이다. 채널간의 정보 공유에 더해 output의 채널 개수를 조절할 수 있다.

Depthwise Separable Convolution을 통해서 연산량을 8~9배 줄이면서도 성능을 어느정도 유지할 수 있었다.
MobileNetV1에서는 두가지 hyper parameters를 제시한다.
Width Multiplier : Thinner Models
Width Multiplier라고 부르는 α는 각 layer를 얼마나 얇게 만드는지 결정한다. input과 output 채널 개수를 M, N에서 αM과 αN이 된다. α는 0 ~ 1 사이이고 기본 MobileNet에서는 1을 사용한다.
Resolution Multiplier : Reduced Representation
두번째 hyper parameter는 multiplier ρ로, 해상도의 크기를 조절해주는 것이다. 입력 이미지 뿐 아니라, 모든 layer의 해상도를 ρ를 곱해 줄임으로써, 이미지의 해상도를 조절한다. 계산량을 ρ^2에 비례해 줄일 수 있다.
MobileNet V2
Linear Bottlenecks
manifold of interest란, 고차원의 정보는 저차원에 표현이 가능하다고 말하는 개념이다. 개별의 d-channel의 convolution layer에 대해서, low-dimensional sub-space로 임베딩하는 것이 가능하다는 것이다. MobileNetV1에서도 연산량과 정확도의 trade-off를 width multiplier parameter로 확인할 수 있었고, 이는 다양한 effcient model designs에 포함되었다. 이러한 가정은 width multiplier가 manifold of interest가 모든 영역의 정보를 포함할 수 있는 만큼 activation space에의 차원을 줄일 수 있다는 뜻이다.
논문에서는 ReLu 함수에 대한 이야기를 하는데, ReLu는 음수 영역은 0으로 만드나, 양수 영역에서는 linear transformation의 형태를 띄기 때문에 양수는 ReLu를 통과해도 정보가 보존된다고 생각할 수 있다고 한다. ReLu를 사용하면 각 채널에서는 음수를 0으로 만들기에 정보의 손실이 필연적으로 발생할 수 밖에 없지만, 많은 채널을 사용할 경우 정보 보존이 가능하다고 이야기한다.

위 그림을 보면, 채널이 2, 3인 경우 많은 정보를 손실하지만 15 이상인 경우 거의 모든 정보를 보존하고 있는 것을 볼 수 있다.
이러한 개념을 배경으로, MobileNetV2에서는 Linear Bottlenecks 구조를 설계했다.
앞의 내용을 짧게 정리하자면, 입력에서 중요한 정보로 볼 수 있는 manifold of interest는, 저차원에서 표현될 수 있고 이러한 정보를 전달하기 위해서는 Linear Transformation 구조를 사용해야한다고 말하고 있다. 특히, bottleneck 내에 있는 ReLU, 특히 저차원에서 사용되는 ReLU의 경우 너무 많은 정보를 파괴하는 경향이 있으므로, bottleneck 구조에서 제외한다고 말한다. 이를 통해 네트워크의 크기를 줄여 연산량을 줄이고, 정확도는 유지할 수 있는 전략을 채택한다.
참고로, MobileNetV2 에서 Linear Bottleneck 구조는 엄밀히 말하자면 inverted Residual blocks의 마지막 1x1 convolution을 하는 layer이다.

Inverted Residuals
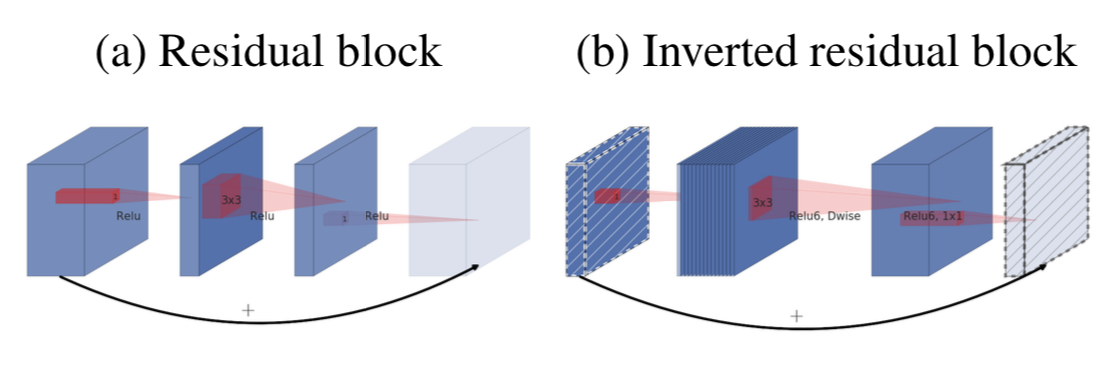
Inverted Residual 이란, 기존에 ResNet에서 사용되던 Residual Block의 순서를 뒤집은 구조이다. 앞의 Linear bottleneck 구조에 대해서 설명할 때, 저차원의 데이터에 이미 manifold of interest가 내재되어 있다고 가정했다. 그래서 기존 Residual Block에서 넘겨주는 layer가 Wide 였다면, Inverted Residuals 에서는 Narrow를 선택한다. 이를 통해 Narrow - Wide - Narrow의 형태를 띄게 된다. Inverted Residual Block은 이러한 구조를 통해 Residual Block에 비해 더 낮은 연산량을 가질 수 있게 된다.
Arichitecture
Inverted Residual Block의 구조

최종적으로 MobileNetV2에서 사용하는 block의 구조는 위와 같다.
1x1 conv with ReLU6 : expansion을 담당한다.
3x3 depthwise conv with ReLU6 : expansion 된 feature map에 depthwise convolution을 해 정보를 추출해낸다.
linear 1x1 conv2d : 여기서는 non-linearlity를 추가해주는 비선형함수 ReLU6를 없앤다. 이를 통해 정보를 안전히 전달함과 동시에 연산량 또한 낮출 수 있다. 또한 이 부분은 기존 MobileNetV1에서는 pointwise convolution에 해당하는데, 비선형함수를 제외했다고 생각하면 된다.
ReLU6를 사용한 이유는 MobileNetV2의 목적과 연관이 있다. MobileNet의 기본 기조는 모델이 다양한 환경, 특히 제한된 모바일, 임베디드 환경에서 잘 작동하도록 하는 것이다. 이에 따라 더 robust 한 모델을 생성하기 위해 ReLU6를 활용했다. 또한 activation의 값을 제한함에 따라 낮은 정밀도 수준의 연산에서도 동작할 수 있기 때문에 활용성이 더욱 올라간다고 할 수 있다.



