
목록전체 글 (19)
ShuyaVision
 [논문 리뷰] DeepLabV3+ (Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation)
[논문 리뷰] DeepLabV3+ (Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation)
DeepLabV3+는 이전 DeepLab 들과 유사하다. DeepLabV2(https://sangbro.tistory.com/11) DeepLabV3(https://sangbro.tistory.com/24) 다만, 기존 DeepLabV2, V3에서는 ResNet을 활용했는데, V3+에서는 Xception을 사용한다. Xception은 Depthwise Separable Conv를 처음으로 소개, 및 사용하는 모델이고, DeepLabV3+에서는 Depthwise Separable Conv에 Atrous 를 결합하여 사용한다. Depthwise Separable Conv에 대한 자세한 내용은 MobileNet 포스팅을 참조하면 된다. MobileNetV1, V2 (https://sangbro.tistory...
 [논문 리뷰] DeepLabV3 (Rethinking Atrous Convolution for Semantic Image Segmentation)
[논문 리뷰] DeepLabV3 (Rethinking Atrous Convolution for Semantic Image Segmentation)
DeepLabv3은 DeepLabv2(https://sangbro.tistory.com/11)와 유사하다. 이에, 어떤 부분을 수정하여 발전시켰는지, 그리고 저자들의 실험에 대해서 중점적으로 작성하려고 한다. DeepLabV2 vs DeepLabV3 총 2가지 부분에서 차별화를 두었다. 1. ASPP(Atrous Spatial Pyramid Pooling)의 Rate 비율이 다르고, Sum이 아닌 Concat을 사용한다. 2. GAP(Global Average Pooling) 기법이 도입되었다. DeepLabV2에서의 Figure이다. ResNet 마지막 몇 Conv Layer를 없애고, 위 구조의 ASPP를적용한다. 기존 이미지의 1/16 수준의 feature map의 크기에서 ASPP를 진행한 후에 ..
 [논문 리뷰] Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
[논문 리뷰] Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
Abstract & Introduction 기존의 Transformer를 Vision task에 적용하기에는 크게 2가지 문제점이 있다고 말한다. 첫번째로는 visual entities의 scale이 text에 비해 다양하다는 점이다. NLP에서는 word를 embedding한 token 형태로 사용하기 때문에 크기를 고정적으로 활용하고, 기존의 Transformer 들은 대부분 이를 기반으로 구성되어 있다. 하지만 visual entities는 환경, 이미지의 종류에 따라 scale이 다양하게 잡히는 경우가 많다. 특히 Object Detection과 같은 경우, DETR에서는 작은 물체를 잡지 못하는 문제점이 존재했듯, visual elements는 scale에 따라 크기가 따라 변하기 때문에 NLP..
 [논문 리뷰] Deformable DETR (Deformable Transformers for End-to-End Object Detection)
[논문 리뷰] Deformable DETR (Deformable Transformers for End-to-End Object Detection)
Deformable DETR은 DETR의 다음 모델이다. Deformable DETR은 'deformable'이라는 개념을 도입해서 모델의 성능을 향상시킨다. 고정된 Attention 구조를 가진 DETR과 달리, 가변적인 Attention 구조를 사용한다. 이를 통해 이미지의 특정 영역에 초점을 맞추게 해서 더 효율적인 feature 학습과 더 나은 객체 검출 성능을 가능하게 한다. 또한 DETR에서 문제점으로 지적되었던 느린 학습 속도와 작은 객체를 잡지 못한 문제점을 해결한다. Deformable Convolution Deformable DETR은 deformable convolution에서 deforamable 개념을 도입해왔기 때문에, 먼저 Deformable convolution을 정리한다. ..
 [논문 리뷰] MobileNetV3, MobileNetEdgeTPU
[논문 리뷰] MobileNetV3, MobileNetEdgeTPU
MobileNetV3 Efficient Mobile Building Blocks MobileNetV1에서는 Depthwise Separable Convolution을 제안해 기존의 convolution을 대체한다. MobileNetV2에서는 linear bottleneck & inverted Residual structure를 제안했다. MNasNet은 bottleneck 구조에 squeeze and excitation 모듈에 기반해 light weight attention module을 제안했다. (MNasNet에 대한 짧은 설명은 게시글 아래 작성했다) MobileNetV3에서는 위 layer들을 조합해 building block으로 사용하며, 효율적인 구조를 제안한다. 그림을 보면, MobileNe..
 [논문 리뷰] K-Net: Towards Unified Image Segmentation
[논문 리뷰] K-Net: Towards Unified Image Segmentation
Abstract 본 논문은 Semantic, instance, panoptic segmentations의 유사한 task들에 대해 효과적인 framework을 제시한다. 이 Framework의 이름은 K-Net으로 instance와 semantic 카테고리에 대해 segments를 수행한다. 이는 learnable kernels 그룹을 통해 이루어지며 각 kernel은 잠재적 instance와 stuff class에 대한 mask를 유동적으로 생성해낸다. 다양한 instances를 구분하는 데 어려움을 해결하기 위해 우리는 input image에 있는 의미있는 group에 대해 각 kernal이 dynamic하고 conditional하게 update할 수 있는 전략을 제시한다. K-net은 biparti..
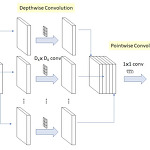 [논문 리뷰] MobileNet V1, V2
[논문 리뷰] MobileNet V1, V2
Mobile 및 Embedded System에서 사용할 수 있도록 개발된 MobileNet의 V1, V2에 대해 간단하게 알아본다.MobileNet V1Depthwise Separable ConvolutionMobileNet model은 depthwise separable convolutions에 기반한다. 이는 depthwise convolusion과 pointwise convolution을 합친 것이다. - depthwise convolution Standard convolution을 factorize 해서 사용하는 방법이다. MobileNet에서는 각 input channnel에 대해 하나의 filter를 사용한다. 이 때 채널간의 정보 공유는 일어나지 않는다. - pointwise convolut..
 [논문 리뷰] DeepLab v2 (Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs)
[논문 리뷰] DeepLab v2 (Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs)
논문 이름에 그대로 나와 있듯이, DeepLab 논문은 크게 3가지 기술을 통해 Segmentation을 한다. 첫번째는 Deep Convolutional Neural Network로, VGG-16, ResNet 등의 pre-trained 된 모델을 사용한다. 두번째는 Atrous convolution이다. Dilated Convolution이라고도 부르며, 필터의 간격을 늘려 넓은 영역의 context를 포착하면서 resolution을 유지한다. 이를 통해 segmentation에서 더 정확한 결과를 얻을 수 있다. 마지막으로는 CRFs라고 부르는 Fully Connected Conditional Random Fields이다. 모델의 출력을 후처리하는 방식으로, 가까운 픽셀들 간의 공간적인 상관관계를 ..